照片+音频 AI-> 视频
简介
在最近这2年中,AI人工智能从Chat GPT面世以来在各个领域都取得了显著的进展。随着技术的发展以及不仅仅只限于自然语言文本回答,开始有更多多模态的类型出现,文字生成图像(Midjourney),文生视频(sora至今没上线,可能是算力不足以公开),以及本文的重点图像生成视频(SadTalker)
效果展示
先来一段网上的宣传视频
我就是被网图欺骗认为真的可以达到这么逼真的程度,于是接下来就有我的折腾之旅
下面是官网示例
环境搭建
看了官网的示例感觉这差距确实太大了
于是下载下来手动跑一遍,毕竟实践出真理
clone仓库
git clone https://github.com/OpenTalker/SadTalker.git
也可以进入SadTalker Github手动下载
cd SadTalker
切换到dev分支(dev分支才是最新的有视频参照功能)
git checkout dev
需要提前装好Conda,没有安装可以在https://docs.anaconda.com/free/miniconda/#id2 点击下载对应版本安装Miniconda
创建python3.10环境
conda create -n sadtalker python=3.10
如果遇到Proceed 询问是否继续按y继续
切换到刚刚创建的sadtalker环境
conda activate sadtalker
当看到左边括号内变成sadtalker则切换成功

切换到你当前下载的对应SadTalker目录

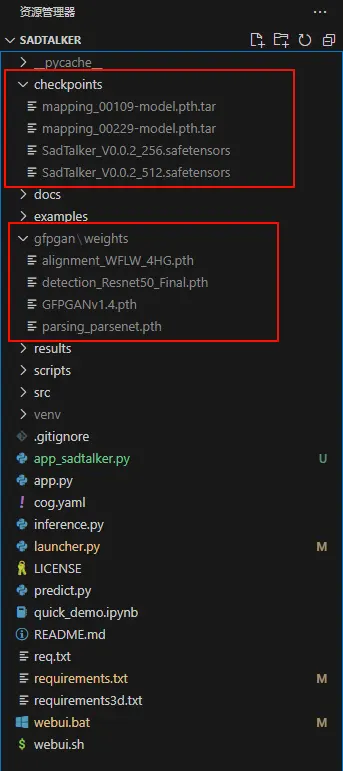
然后下载模型
-
Baidu (百度云盘) (Password:
sadt)
下载好后如图所示放在SadTalker文件夹下,没有checkpoints文件夹需要自己手动创建
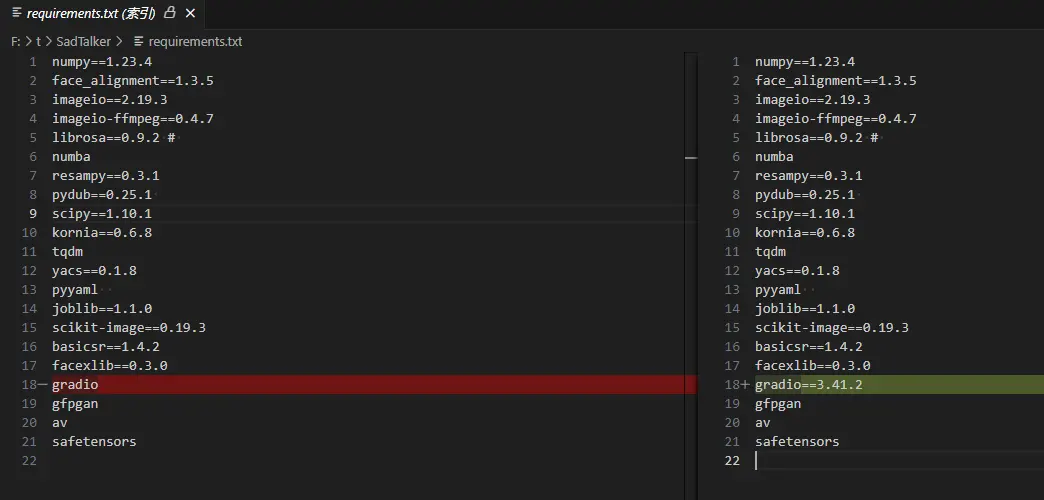
更改requirements.txt的依赖版本
gradio==3.41.2
Windows运行
.\webui.bat
Mac/Linux运行
./webui.bat
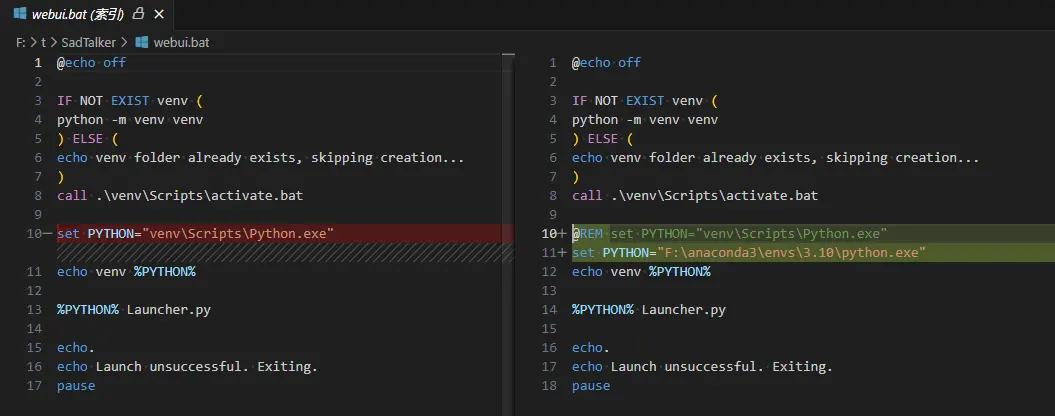
如果失败了,则更改下python环境,我这里是找到我之前下载的3.10版本的python路径强制写死
运行成功后你会看到这个提示,打开网址
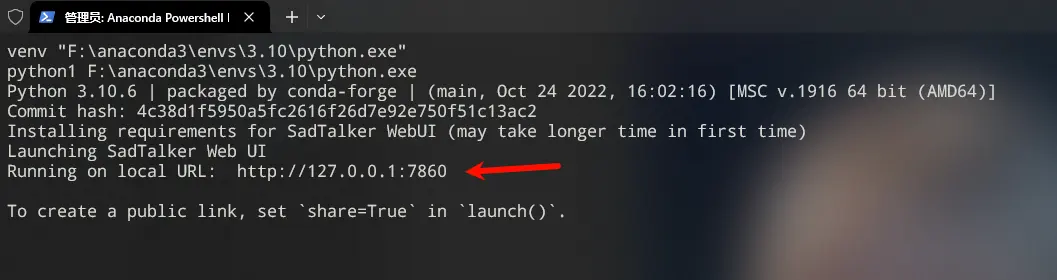
就可以自己上传图片和语音进行合成视频了
生成效果
这是我刚开始使用图片和音频生成的

这效果实在太差了
后面更改成resize模式自动调整头部图像,不过这效果仍然一言难尽
经过多次尝试才发现是我的音频无法正常的识别,干扰噪音太多了
于是换成了ai文字生成的语音,可以使用这个在线网址 https://ttsmaker.cn/
生成后的效果虽然不是很完美,但对比之前生成的已经好多了 (没有对比就没有伤害😂)
接着我也调研了国内做的比较好的 通义的EMO https://humanaigc.github.io/emote-portrait-alive/
可惜还只是宣传,没有开源也没有实际可用的程序,不过他们是将该技术用在了通义的App中
随后我下载了App并上传图片生成了两个视频
可以明显看出效果已经很好了,但是目前是不支持上传音频和视频作为素材的。也就是内部是固定好几个效果比较好的音频和视频素材,然后再根据用户上传的图片来生成视频。
总结
虽然现在AI图片转视频还没有那么成熟,但目前效果也是可以接受的,相信随着科技的进步,这种技术将会越来越多的被广泛使用。比如,一个室内设计师可以通过AI将设计的立体图像转换成一段视频,让客户从各个角度审视他们未来的居家环境。摄影师也可以利用这项技术为他们的作品增加动态元素,使图片生动活泼起来。
在未来,这只是AI发展的冰山一角。人工智能的应用领域将会扩大到我们生活的各个角落,从汽车、医疗、娱乐,到教育、科研、社交等。其中,深度学习、自然语言处理、机器学习等领域尤其被看好。它们将越来越成为我们日常生活和工作的一部分。
作为程序员,我们不一定有能力需要创造出新的AI模型,但我们可以将已有的事务和AI的技术能力相结合,也就是颠覆性创新和组合创新的区别。无论从事哪个行业,我觉得都应该拥抱AI,学习AI,并使用AI,虽然现在AI还并不是那么的强大,但已经是个很好的工具可以辅助我们提高工作的效率,期待AI会给我们带来更美好的未来。